Project Description
Here I will present an interesting project with causality and causal representation learning; GCRL: Generative Causal Representation Learning for Out-of-Distribution Motion Forecasting.
Key Contributions
- Collaborated with multiple academic partners to shape research directions and integrate feedback.
- Mentored a PhD student throughout the research project, including experimental design and model development.
- Provided strategic guidance on methodology and technical implementation.
- Supported the writing, revision, and submission of a peer-reviewed article.
- Shared authorship and contributed to research dissemination through publication and presentation.
Code / Git
Research / Paper
Presentations
Additional Context
In this section, I will explain the fundamentals of causality and causal models required to better understand the ideas of these projects.
Structural Causal Models (SCMs)
Structural Causal Models (SCMs) are a way of describing causal features and their interactions, which are represented by Directed Acyclic Graphs (DAG) (Pearl et al., 2016).
We say that X is a direct cause of Y when there is a directed edge from X to Y in the DAG. The cause and effect relation X → Y tells us that changing the value of X can result in a change in the value of Y, but that the reverse is not true.
A causal model receives as inputs:
- A set of qualitative causal assumptions (A)
- A set of queries concerning the causal relations among variables (Q)
- Experimental or non-experimental data (D), presumably consistent with (A).
A causal model makes predictions about the behavior of a system. The outputs of a causal model are:
- A set of logical implications of (A)
- Data-dependent claims (C) represented by the magnitude or likelihoods of the queries (Q)
- A list of testable statistical implications (T).
Causal Variables
In causal analysis, variables are categorized into endogenous and exogenous variables, each playing distinct roles in understanding causal relationships.
- Endogenous Variables:
Endogenous variables are influenced by other variables within the system. Their values are determined by interdependencies and causal relationships within the model. For example, in an economic model, consumer spending (Y) is an endogenous variable influenced by income (X), where an increase in income generally leads to an increase in spending.
- Exogenous Variables:
Exogenous variables are determined outside the system being studied and do not depend on other variables in the model. They serve as external inputs that can affect endogenous variables. For instance, in the same economic model, factors like government policy changes or interest rates (X) can influence income but are not affected by consumer spending.
Causal Representation Learning (CRL)
Causal Representation Learning (CRL) is an emerging field within machine learning and artificial intelligence that focuses on learning representations of data that explicitly capture the underlying causal structures and relationships among variables. The goal is to improve understanding and predictions of complex systems by leveraging causal knowledge rather than solely relying on correlations.
- Causality vs. Correlation:
Traditional machine learning often relies on correlations between variables, which can lead to misleading conclusions. For example, two variables may be correlated without one causing the other. CRL aims to identify causal relationships, helping to distinguish true causes from mere associations.
- Structural Causal Models (SCMs):
SCMs are a mathematical framework used in CRL to represent causal relationships through Directed Acyclic Graphs (DAGs). Each node in the graph represents a variable, and directed edges indicate causal influences. This graphical representation enables clear understanding of how changes in one variable can affect others.
- Causal Inference:
CRL incorporates techniques from causal inference, which involves drawing conclusions about causal relationships from data. This often involves interventions (manipulating variables) and counterfactual reasoning (considering what would happen under different circumstances).
- Interventions and Do-Calculus:
Interventions (denoted as do-operations) are essential for causal analysis. CRL seeks to learn representations that can effectively simulate the effects of interventions on various variables. Do-calculus provides a formal framework for reasoning about these interventions.
- Latent Variables:
CRL often deals with latent variables—unobserved factors that influence observed data. By capturing these latent structures, CRL can provide richer, more nuanced representations that enhance the model's predictive power.
- Implicit vs. Explicit CRL:
- Explicit Causal Representation Learning involves direct modeling of causal relationships using known structures, such as SCMs or DAGs. When the causal graph is known, we can specify relationships directly, enabling accurate causal inference and intervention simulation.
- Implicit Causal Representation Learning refers to inferring causal relationships from data without a clearly defined causal graph. This approach often relies on statistical techniques and causal discovery algorithms to hypothesize causal structures from observed correlations. The challenge lies in identifying true causal relationships amidst potential spurious associations.
Confounders
In the context of causal graphs, confounders are variables that can influence both the independent variable (the cause) and the dependent variable (the effect), leading to a spurious or misleading association between them. Confounders can create a false impression of a causal relationship between variables that may not actually exist. Confounders are variables that are not included in the causal model but are related to both the independent and dependent variables.- Role in Causal Inference: Confounders can obscure or exaggerate the true causal relationship between variables, making it challenging to accurately identify and quantify causal effects.
- Identification: To correctly infer causal relationships, it's crucial to identify and control for confounders in the analysis. This often involves statistical techniques or domain knowledge to account for these variables.
- Example: Suppose you are studying the effect of exercise on weight loss. If you don’t account for diet, which influences both exercise habits and weight loss, you might incorrectly attribute changes in weight solely to exercise when diet also plays a significant role. In this case, diet is a confounder.
- Adjustment: In causal graphs, confounders are usually represented and accounted for to ensure that the relationships between variables are accurately estimated. Techniques such as stratification, regression, or matching can be used to adjust for confounding effects.
Backdoor Criterion
The backdoor criterion is a fundamental concept in causal inference, particularly when using Structural Causal Models (SCMs) and Directed Acyclic Graphs (DAGs). It provides a method to identify a set of variables that, when controlled for, can help estimate the causal effect of one variable on another, effectively eliminating confounding.
- Definition:
The backdoor criterion states that a set of variables Z satisfies the backdoor criterion relative to two variables X and Y if:
- Z blocks all backdoor paths from X to Y (i.e., paths that go into X and then to Y).
- Z does not include any descendant of X.
- Backdoor Paths:
A backdoor path is a path that connects X to Y that goes backwards through other variables (i.e., it starts with X and then moves to a variable that leads back to Y). Backdoor paths can introduce confounding bias in estimating the causal effect from X to Y.
- Causal Effect Estimation:
By controlling for the variables in Z that satisfy the backdoor criterion, you can estimate the causal effect of X on Y using the expression p(Y | do(X)), which represents the distribution of Y when X is intervened upon (i.e., manipulated directly rather than just observing it).
- Example:
Consider the following variables in a DAG:
- X: Treatment (e.g., a new medication)
- Y: Outcome (e.g., health improvement)
- Z: Confounding variables (e.g., age, pre-existing health conditions)
If both Z and another variable S affect both X and Y, then Z satisfies the backdoor criterion because it can block the backdoor paths from X to Y. By controlling for Z, you can obtain a more accurate estimate of the causal effect of X on Y.
GCRL: Generative CRL for Out-of-Distribution Motion Forecasting
In the first project we propose a novel generative model to address domain shifts in motion prediction tasks.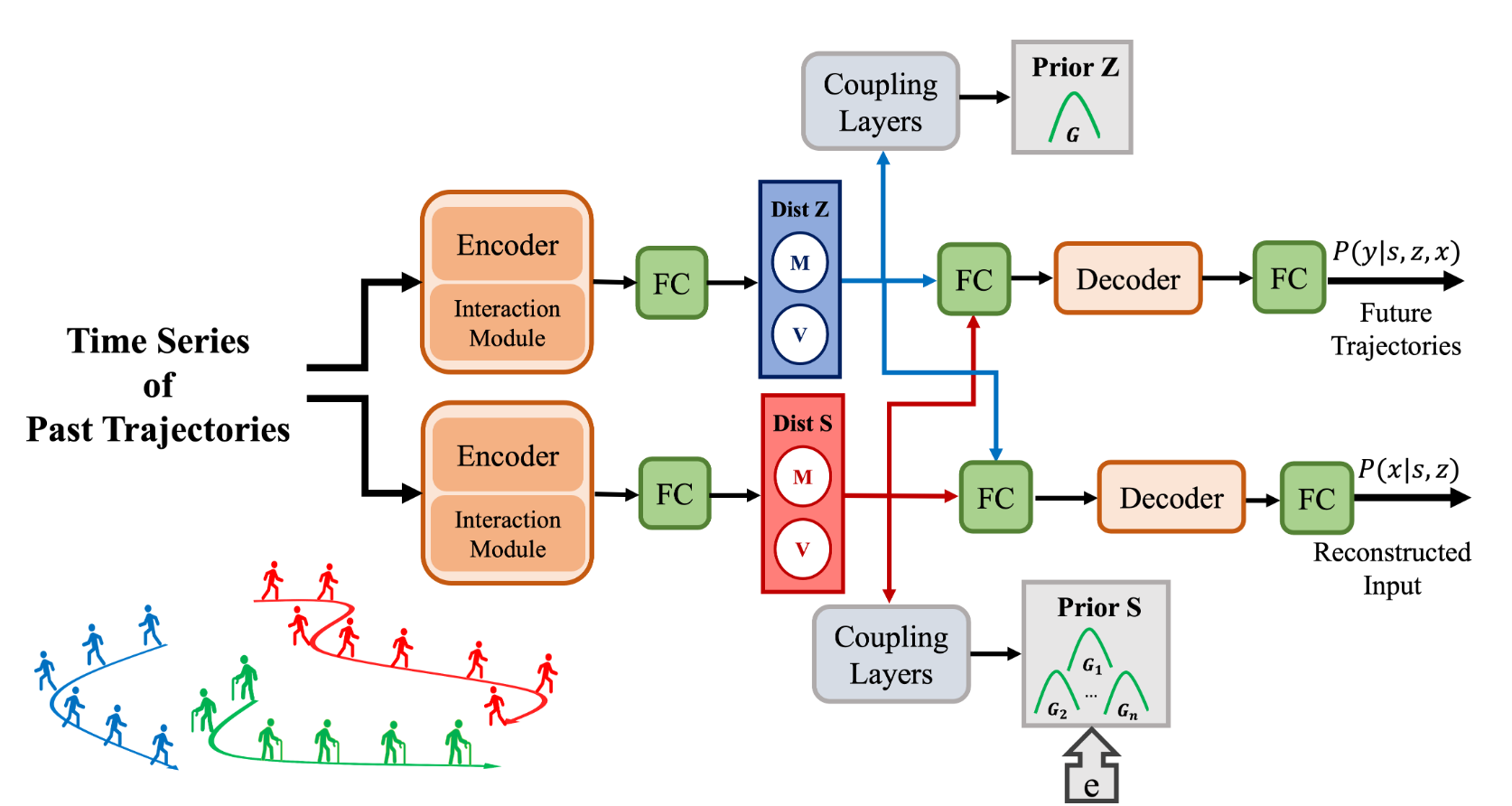
Causal formalism
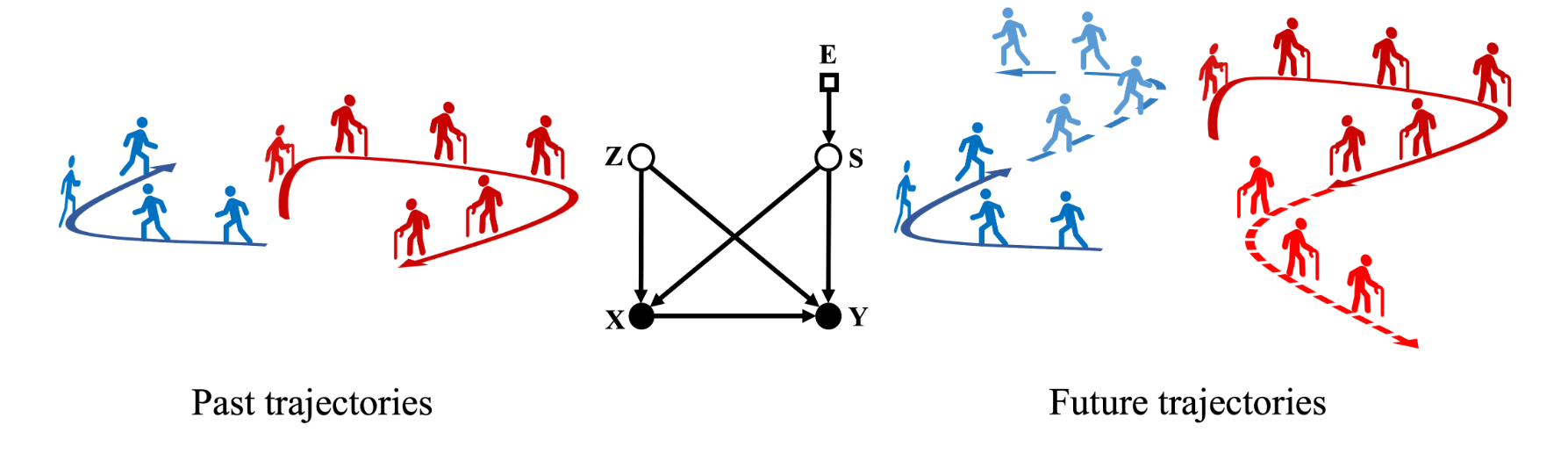
Figure (2) illustrates our proposed causal formalism for this project. Shown by figure (2) (center), we assume a known SCM, and two causal variables, which affect trajectories of the pedestrians:
- Invariant features do not vary across domains but can influence the trajectories of the pedestrians. These features can be associated with physical laws, traffic laws, social norms, and etc.
- Variant features vary across domains and can be associated with the motion styles of the pedestrians in an environment .
Moreover, we consider four endogenous variables for different representations:
- S for variant features (unobserved/latent)
- Z for invariant features (unobserved/latent)
- X for past trajectories (observed)
- Y for future trajectories (observed)
We also introduce an additional exogenous variable shown by E as the selection variable to account for the changing factors in each environment. The selection variable acts as an identifier of an environment. In other words, we assume that all members of the dataset are sampled from a parent distribution over X, Y , and E.
Furthermore, we assume that the proposed model is causally sufficient where it explains all the dependencies without adding further causal variables.
Knowing the context of our causal model, the following conditions must be satisfied, which results in the edges formation of the causal graph:
- There should be an edge from S to X and Y because motion styles can influence the speed of the pedestrians.
- There should be an edge from Z to X and Y because social norms can influence how closely pedestrians move next to each other.
- There should be an edge from X to Y because the location in the past determines where the pedestrian is going to be in the future.
- S varies in each domain, hence, there should be an edge from selection variable E to S to account for all the changing factors in each domain.
Learning latent variables
As shown by Figure (2), S and Z confound the causal effect of observed variables X and Y. Therefore, we need to eliminate the confounding effect by using the backdoor criterion, and computing the causal effect of X on Y as p(Y|do(X)).Loss function
Our final objetive function is as follows:\( \text{loss} = \max_{p,q} \, \mathbb{E}_{p^*(x,y)} \left[ \log q(y|x) + \frac{1}{q(y|x)} \, \mathbb{E}_{q(s|x), q(z|x)} \left[p(y|x,s,z) \log\left(\frac{p(x|s,z) \, p(s) \, p(z)}{q(s|x) \, q(z|x)}\right)\right] \right] \)
where the loss is designed to address the following objectives if the optimal loss obtained:
- To minimize the distance between ground-truth future trajectories Y and predicted future trajectories via maximizing the log likelihood posterior \(\log q(y|x)\).
- To eliminate the confounding effect by estimating the causal effect of X on Y through \(\log q(y|x) = \mathbb{E}_{q(s|x), q(z|x)} p(y|x,s,z) = p(y|do(x)) \)
- Reconstruction of the past trajectories X through maximizing \(\log(x|s,z)\)
- Invariant representation learning through maximizing \(\log {\frac{p(z)}{q(z|x)}}\). Possible if q(z|x) = p(z) which means posterior equals prior.
- Variant representation learning through maximizing \(\log {\frac{p(s)}{q(s|x)}}\). Possible if q(s|x) = p(s) which means posterior equals prior.
As discussed earlier latent variable S varies in each domain, so is domain-specific. Therefore, we model its prior with a Gaussian Mixture Model GMM, which are proven to be identifiable. Moreover, GMMs are universal approximators, hence, \(q(s|x)\) will be capable of producing arbitrary variant features
On the other hand latent variable Z is invariant and is the same in all domains, so we model its prior with a single Gaussian distribution.
Domain Adaptation
After the model is trained using our objective function, \(q(z|x)\) will generate representations with a single Gaussian distribution and \(q(s|x)\) will generate representations with a Gaussian Mixture Model (GMM) distribution. Therefore, all representations generated by \(q(z|x)\) will be in the same range, whereas the representations of \(q(s|x)\) will form clusters, each modeled by a component of the GMM.
What needs fine-tuning?
Since S can be interpreted as a weighted sum of the representations learnt from different environments of the training domains, which may be used in the test domains as well. Depending on how related the test domains are to the training domains, we may need to fine-tune the components of the S prior (GMM) to obtain a new prior for S. The models to predict future trajectories \(p(y|x, s, z)\) and to reconstruct past trajectories \(p(x|s, z)\) also needs to be fine-tuned as the samples of \(q(s|x)\) will be updated. Thus, we fine-tune \(p(y|x, s, z)\), \(p(x|s, z)\), \(q(s|x)\) and p(s).
What needs no fine-tuning?
Since Z is invariant, we can directly transfer it to the new domain without any fine-tuning. Thus \(p(z)\), and \(q(z|x)\) do not require fine-tuning, so they can be arbitrary complex.
How to conduct inference?
To fine-tune the model at inference time, we reuse the loss function without the regularizing Z posterior by omitting \(q(z|x)\). Eventually, \(q(s|x)\) will be driven towards the new prior and compensate for the domain shift in the test domain.Experiments
1-Robustness
We add a third dimension to the coordinates of pedestrian to measure observation noise and is modeled as:\(\gamma_t := (\dot{x}_{t+\delta t} - \dot{x}_t)^2 + (\dot{y}_{t+\delta t} - \dot{y}_t)^2\)
\(\sigma_t := \alpha(\gamma_t + 1)\)
where \(\dot{x}_t = x_{t+1} - x_t\) and \(\dot{y}_t = y_{t+1} - y_t\) reflect the velocity of the pedestrians within the temporal window length of \(\delta t = 8\), and \(\alpha\) is the noise intensity. For the training domains, \(\alpha \in \{1, 2, 4, 8\}\) while for the test domain, \(\alpha \in \{8, 16, 32, 64\}\). The test domain is the eth environment for this experiment. The results in Table 1 Gale Bagi et al., 2023. demonstrate the robustness of our method against observation noise while performing comparably with other motion forecasting models for low \(\alpha\).
2-Domain Generalization
To test domain generalization capabilities of GCRL, we consider the Minimum Separation Distances (MSD) in the training and test domains are \(\{0.1, 0.3, 0.5\}\) and \(\{0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8\}\) meters, respectively. As illustrated in Figure 6 Gale Bagi et al., 2023, our method is more robust to domain shifts compared to baseline, and it is achieving slightly better ADE, which is 8.8% on average. For OOD-Inter cases, where the test domain shift falls within the range of training domain shifts (e.g., test domain shift = 0.4), GCRL remains reusable as ADE shows insensitivity to these shifts. However, for OOD-Extra cases, where test domain shifts lie outside the range of training domain shifts, the model requires fine-tuning to maintain performance.
3-Domain Adaptation
To evaluate the efficiency of our proposed method for knowledge transfer using a synthetic dataset under an OOD-Extra case. We train both baseline and GCRL with a consistent setup and fine-tune various model components using a limited number of batches from the test domain. Each batch contains 64 samples, resulting in fine-tuning with sample sizes of \(\{1, 2, 3, 4, 5, 6\} × 64\). For baseline, we fine-tune with the optimal settings reported in their paper. For GCRL, we fine-tune the components \( p(y|x, s, z) \), \( p(x|s, z) \), \( p(s) \), and \( q(s|x) \).
As illustrated in Figure 7 Gale Bagi et al., 2023, GCRL adapts to the new environment more rapidly and demonstrates greater robustness to OOD-Extra shifts compared to baseline, improving evaluation metric by an average of 34.3% over baseline.
4-Generative Bonus
Since GCRL is a generative approach, we can generate multiple future trajectories per sample and select the best of them to tackle the multi-modality of trajectories. Therefore, we use a hyper-parameter N in testing to determine the number of generated trajectories per sample. Figure 4 Gale Bagi et al., 2023 illustrates the significant impact that a generative approach can have in the performance. According to Figure 5 Gale Bagi et al., 2023 the qualitative results also suggest that a generative approach can be useful in motion forecasting as it is able to generate diverse trajectories.